Régression logistique
Le modèle de régression logistique est également l’un des modèles les plus populaires en machine learning pour réaliser un classement ( prédire les valeurs d'une variable qualitative sur base de prédicteurs ). Il s'agit d'une technique paramétrique - le modèle doit trouver les meilleurs paramètres au regard des données -.
Cette technique est utilisée pour ajuster la relation entre une variable qualitative ( variable dépendante ) et un ensemble de prédicteurs - variables indépendantes - qui doivent être des variables quantitatives ou des variables qualitatives transformées en variables quantitatives ( encodage one-hot ou numérisation de variables discrètes ).
Le fonctionnement de la régression logistique est quasi identique à la régression linéaire si ce n'est qu'elle utilise une fonction sigmoïde. Tout comme la régression linéaire, nous partons du postulat que et sont dépendants, c’est-à-dire que la connaissance des valeurs des permet d’améliorer la connaissance des valeurs de . Il existe donc une corrélation entre et - pour rappel : au plus une variable est corrélée ( de manière positive ou négative ) à la variable , au plus elle est importante pour notre modèle car on dit qu'elle est « discriminante ». - voir ( corrélation ).
La régression logistique ne prédit pas une valeur qualitative directement mais une probabilité qu'un nouvel enregistrement appartient à une classe.
Linéaire vs logistique
Lorsque l'on évoque le concept de régression, il s'agit de tout processus qui tend à trouver des relations entre les variables.
La régression linéaire cherche à établir une relation linéaire entre la variable dépendante (y) et les variables explicatives ou indépendantes ( ) ( prédicteurs ) Exemple d'une régression linéaire simple : si l’âge de la voiture est de +1, le prix sera impacté de ( selon le coefficient et l’origine de la droite ).
La régression logistique cherche également à établir une relation entre la variable dépendante ( y ) et les variables explicatives ou indépendantes ( ) ( prédicteurs ) **mais utilise une fonction logistique ( le logit ) pour obtenir une valeur entre et soit une probabilité qu'un nouvel enregistrement appartienne à une classe.si l’âge de la voiture augmente de 1 an, la probabilité qu'elle tombe en panne augmentera ou diminuera en fonction du coefficient associé à l'âge dans le modèle..
L'une utilise donc une fonction linéaire alors que l'autre utilise la fonction sigmoïde qui, par une fonction linéaire sous-jacente permet de modéliser une probabilité.
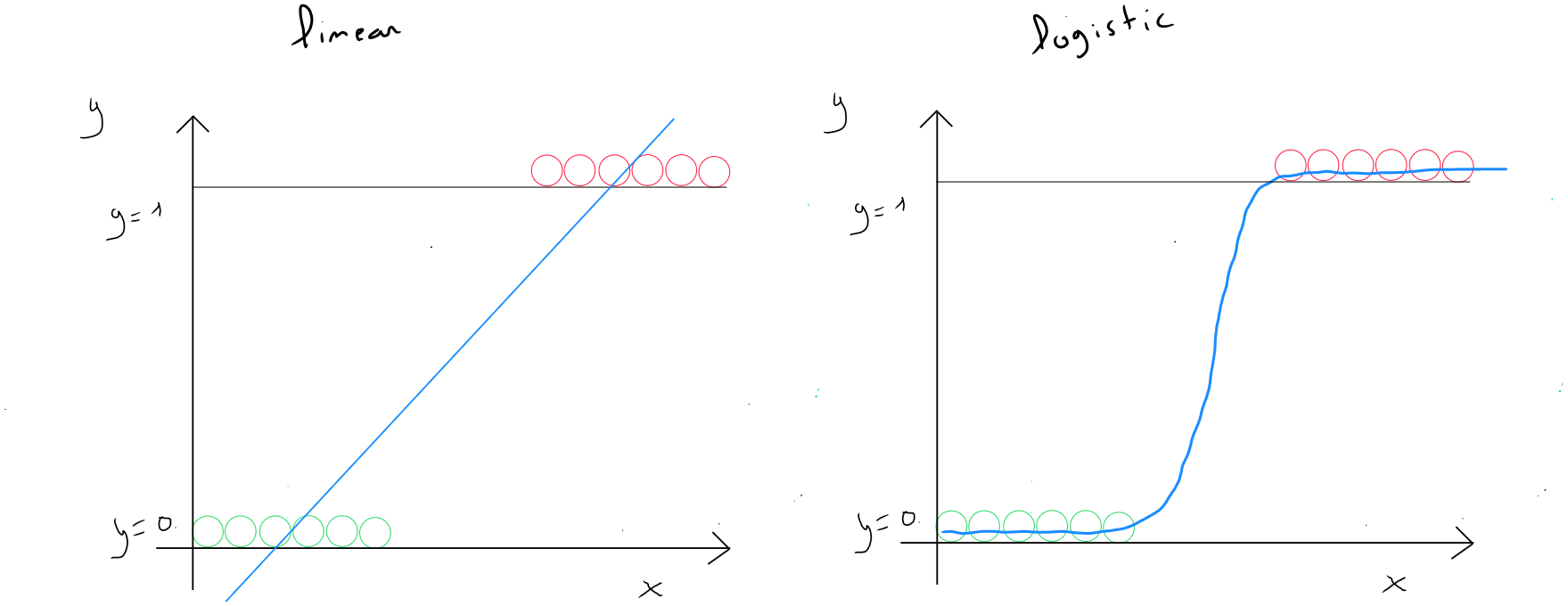
Pourquoi ne pas utiliser une régression linéaire ?
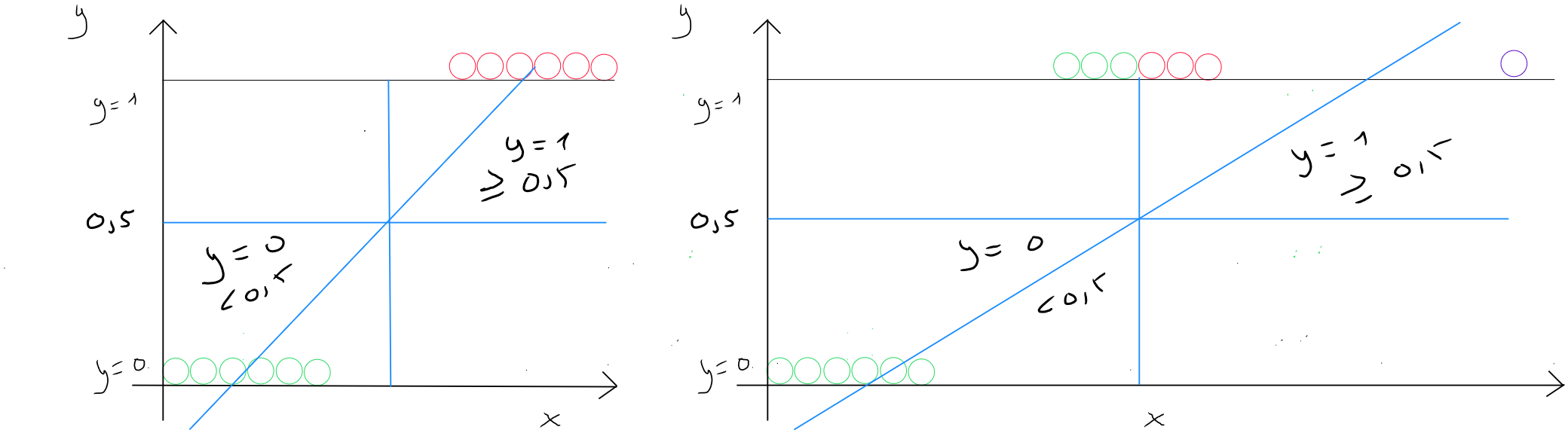
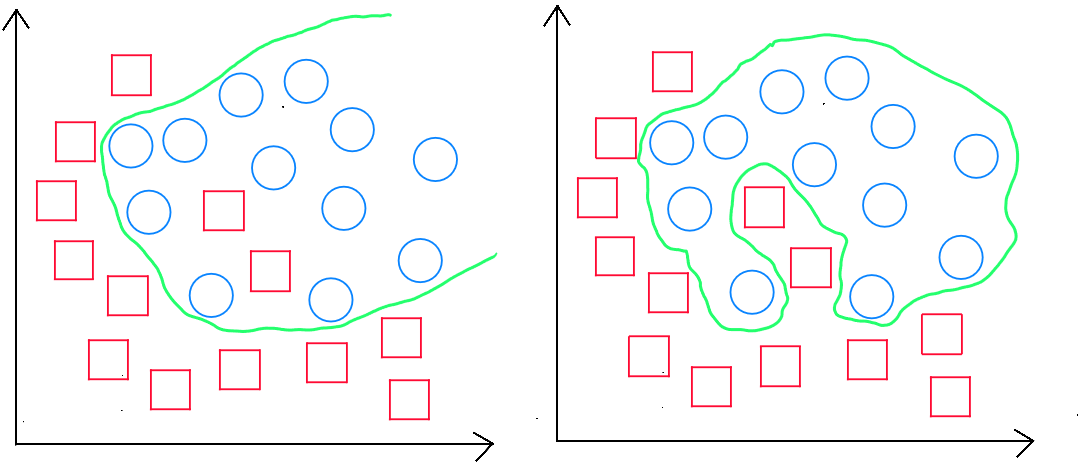
Prenons l'exemple d'un classement à deux valeurs soit ou . J'ai donc une distribution de valeurs pour les deux cas. Si j'utilise une régression linéaire et que je trace la droite. Je pourrais, dans l'exemple illustré ci-dessous à gauche, considérer que la régression linéaire fait un travail correct en partant du postulat que nous définissons un seuil de 0,5 pour dire que toute valeur étant égale ou supérieure à est égale à ( la classe 1 ) et toute valeur inférieure à est égale à ( la classe ). Nous constatons dans le graphique de gauche que toutes les valeurs situées à droite de la perpendiculaire à ont un seuil supérieur ou égal à et donc .
Si tout d'un coup, nous disposons d'un enregistrement dont la valeur de est bien plus importante ( graphique de droite - point mauve ), dans ce cas, la pente de la droite est modifiée et nous constatons que le modèle prédirait une partie des valeurs supérieures ou égales au seuil de comme faisant partie de la classe .
Nous devons donc utiliser une fonction qui nous permet d'obtenir une courbe dont la particularité serait d'appliquer une forme linéaire dans une sous-fonction, lors de l'augmentation exponentielle des valeurs, mais qui à son commencement et à sa fin serait plate de sorte que les valeurs resteraient toujours comprises entre et . Concrètement, il s'agit d'une fonction en forme de S pour assurer que les valeurs possibles soient comprises entre et .
Fonction sigmoïde
La fonction sigmoïde - fonction logistique - est une fonction mathématique en forme de S dont la particularité est de transformer n'importe quelle valeur en un nombre compris entre et .
ou
représente la sous-fonction linéaire. Tout comme la régression linéaire, l'algorithme de la régression logistique dispose de données d'entrainement, c'est à dire des et des et, sur base de ces informations, doit identifier les paramètres grâce à une fonction coût et l'algorithme du gradient descent pour trouver l'optimal local. Lorsque les paramètres sont identifiés, le modèle sigmoïde renvoie en sortie une valeur entre 0 et 1 - une probabilité - qui est transformée en classe sur base de la définition d'un seuil ( majoritairement ).
Réécrite en détail, la formule de nous donne ceci :
et donc la formule de la fonction sigmoïde :
ou
Si nous décortiquons la formule :
- est la sortie de la fonction sigmoïde qui nous permet d'obtenir une valeur entre et ;
- est l'entrée de la fonction - qui contient les paramètres identifiés par l'algorithme du gradient descent sur base des données d'entrainement. requiert également de nouvelles valeurs de pour pouvoir prédire une probabilité ;
- est la constance d'Euler ( valeur approximative de ) et joue un rôle crucial dans l'obtention de la forme en S ;
Peu importe la valeur de , l’exposant négatif de la constante d'Euler au dénominateur fera en sorte que :
- si est une très grande valeur positive , la fonction sigmoïde ramènera à un maximum de ;
- si est une très grande valeur négative , la fonction sigmoïde ramènera à un maximum de ;
Fonction sigmoïde en python
def sigmoid(z):
g = 1/(1+np.exp(-z))
return g
# (z = np.dot(X[i],w)+b) - define later in the cost function
Seuil de décision
La régression logistique nous permet d'obtenir en sortie de la fonction , une valeur comprise entre et et nous devons, en tant que data scientist, définir le seuil de la classe ou la classe . Dans la littérature, le seuil de est souvent mentionné de tel sorte que si la valeur de prédiction est alors et si la valeur de prédiction est alors .
Seuil linéaire
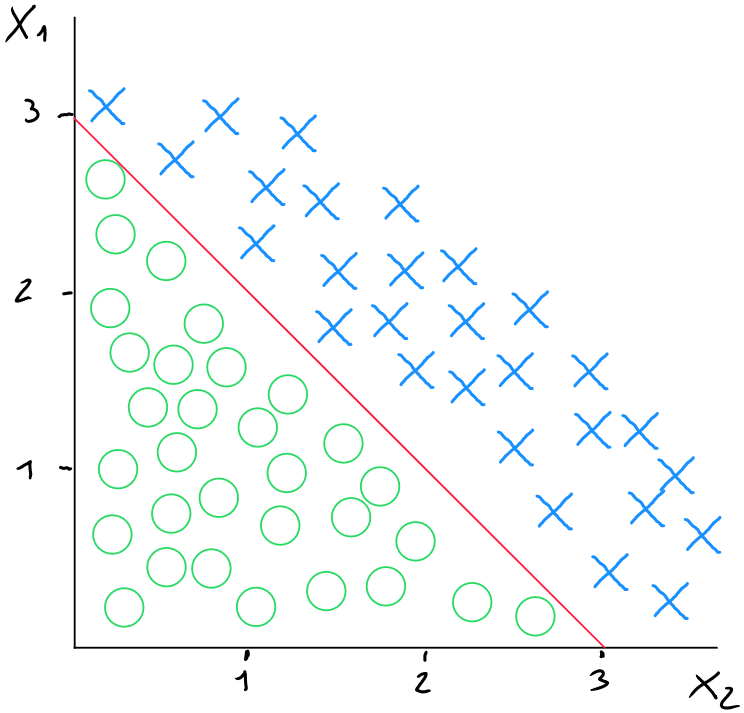
Dans le cas d'une décision de type linéaire sur la base de deux prédicteurs ( ), nous pourrions représenter les données comme suit (schéma ci-dessous) pour les valeurs où , ce qui correspond à
Pour simplifier l'exemple, prenons 1 comme valeur pour et , et - 3 pour .
Le seuil de décision linéaire correspondrait dans ce cas-ci au moment où ; car ce seuil serait neutre pour définir si (croix rouge) ou (rond bleu).
Dans notre cas, étant donné que et valent 1 et que vaut -3, nous pouvons réécrire la formule comme suit : ; Ainsi, .
La formule du seuil de décision linéaire correspond à la formule initiale de la régression logistique :
ou
Seuil non-linéaire
Comme nous l'avons abordé pour la régression polynomiale dans le cadre du chapitre sur la régression linéaire, nous pourrions nous retrouver dans des cas de figure de la régression logistique où la séparation des données est non-linéaire.
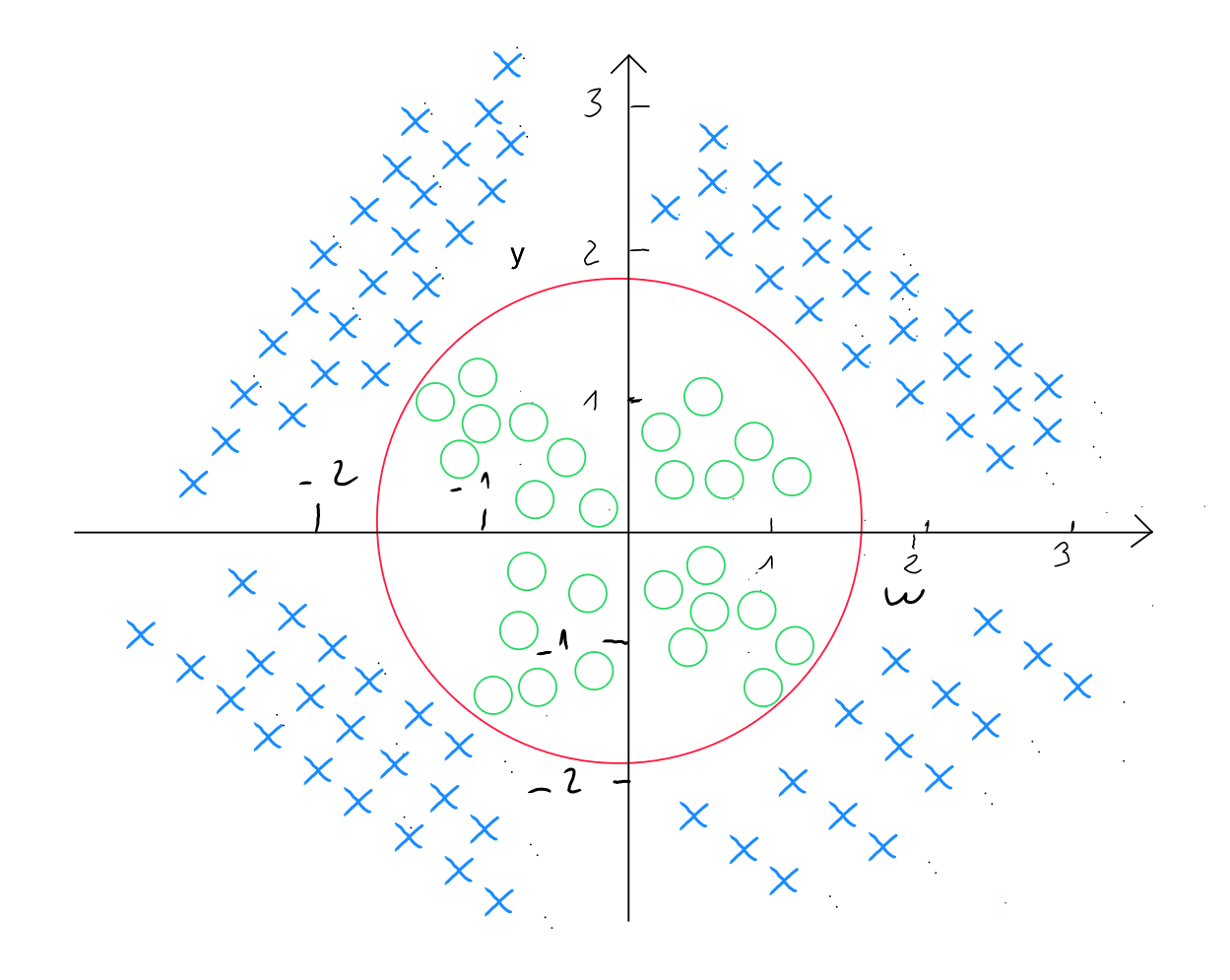
Dans le cadre d'un seuil-non linéaire, nous allons utiliser des caractéristiques polynomiales en adaptant la formule comme suit (pour deux prédicteurs et ) :
soit
D'autres degrés de forme polynomiale sont testés bien entendu dans le cadre de l'algorithme pour pouvoir trouver la meilleure manière de prédire l'information. Par exemple dans les cas suivants :
L'équation prendrait la forme suivante :
Fonction polynomiale en python (Seuil non-linéaire)
import numpy as np
import pandas as pd
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.model_selection import train_test_split
import math, copy
from sklearn.metrics import confusion_matrix
# Chargement des données
data = pd.read_csv('data.csv')
# Séparation des caractéristiques et de la cible
x = data[['x_1', 'x_2', 'x_3', 'x_4', 'x_5', '...', 'x_n']].values
y = data['y'].values
# Génération des termes polynomiaux de degré 3
poly = PolynomialFeatures(degree=3)
x_poly = poly.fit_transform(x)
# Standardisation des données polynomiales
scaler_x = StandardScaler()
x_poly = scaler_x.fit_transform(x_poly)
# Division en ensemble d'entraînement et de test
x_train, x_test, y_train, y_test = train_test_split(x_poly, y, test_size=0.4, random_state=42)
Fonction coût
La forme de la fonction coût d'une régression linéaire est de forme convexe, ce qui est optimal pour l'algorithme du gradient descent dont l'objectif est - par itération - de trouver l'optimal pour les valeurs et .
Dans une régression linéaire, nous retrouvons donc la formule suivante pour la fonction coût :
Le problème de la régression logistique, c'est que la forme de sa fonction coût est non convexe et par conséquent, le gradient descent peut trouver plusieurs optimal local qui ne correspondraient pas forcément à et serait bloqué dans sa convergence.
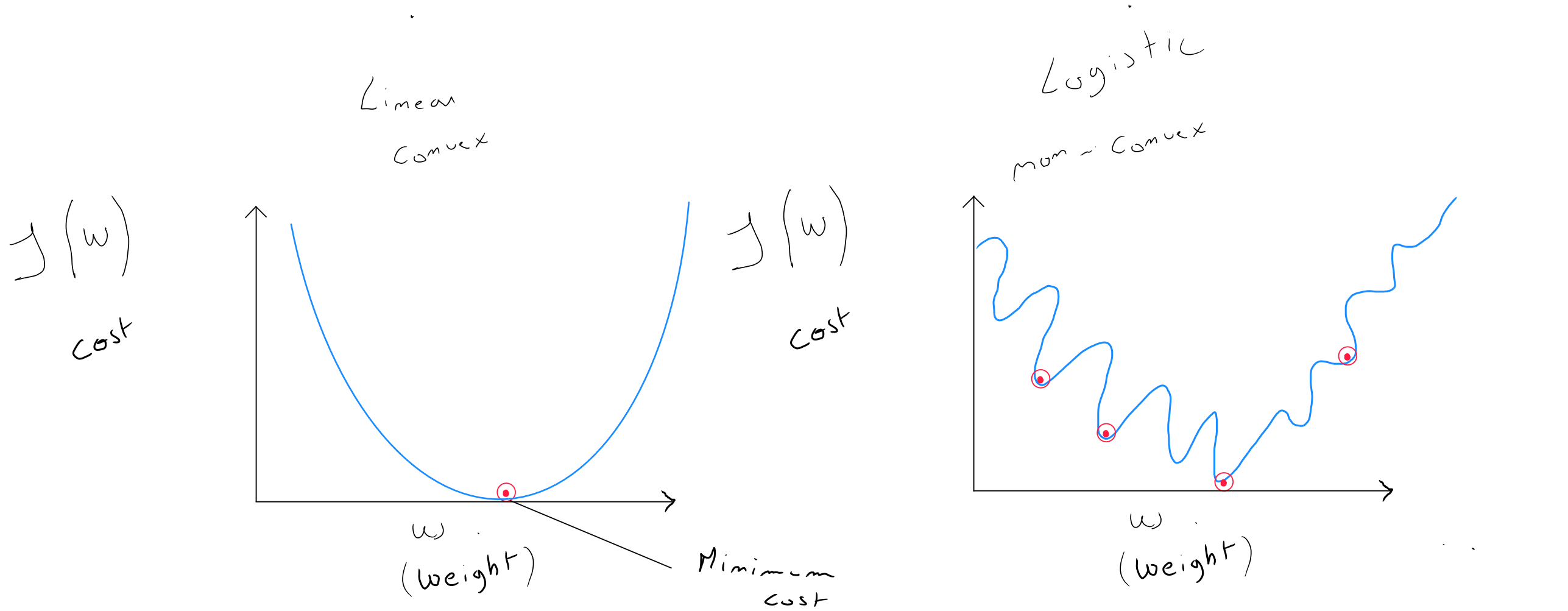
La régression logistique utilise une fonction de coût différente « transformée » de la régression linéaire afin de rendre la forme de la fonction coût convexe à nouveau et permettre de converger vers l'optimal local.
Fonction de perte
Pour adapter la fonction coût à la régression logistique, concentrons-nous sur la notion de perte qui peut s'identifier de manière isolée à la fonction coût , en bleu dans la formule ci-dessous.
Cette fonction perte (loss) pour tous les enregistrements, peut être réécrite comme suit :
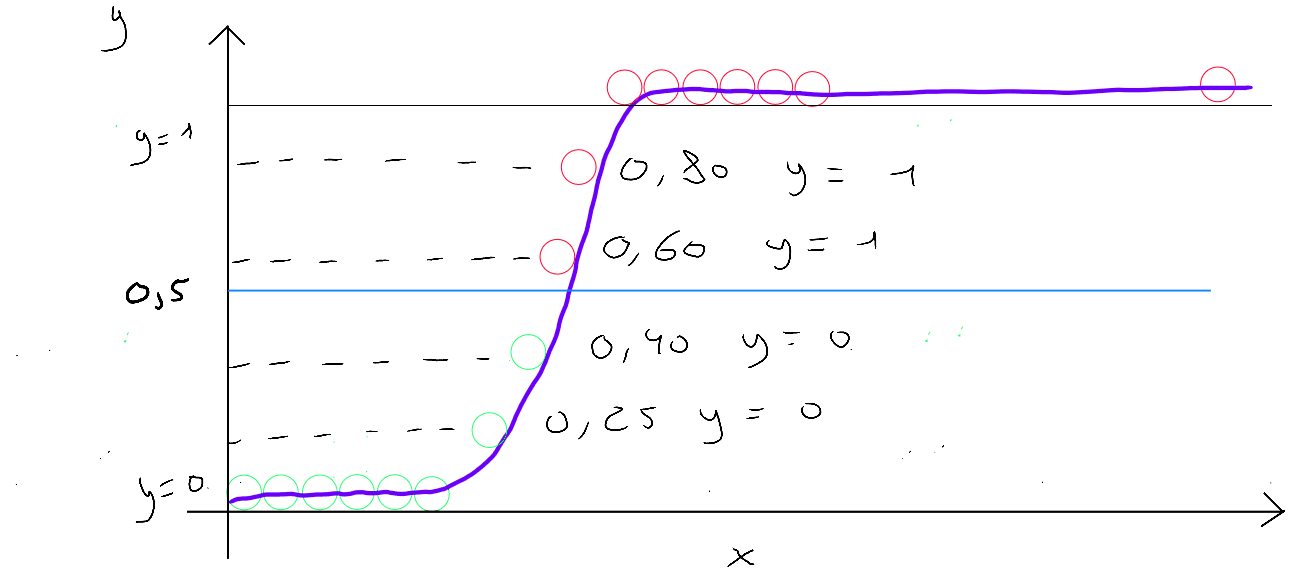
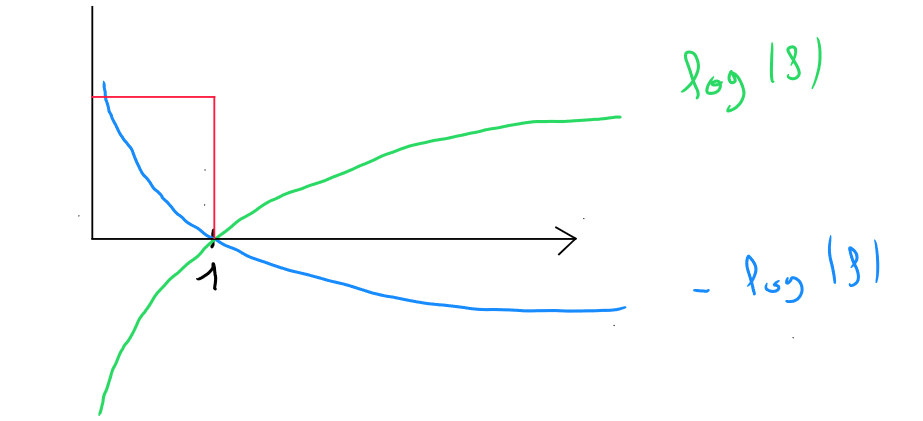
Si nous visualisons en considérant en abscisse (x), - sachant que est le résultat de la régression logistique ( valeur entre et ) -, cela ressemblerait à la courbe verte du schéma ci-dessous ; Et si nous visualisons , nous obtiendrions la courbe bleu.
L'intersection entre les deux courbes sur l'axe des abscisse correspond à la valeur . La partie de la fonction qui porte l'intérêt du résultat entre et est la partie supérieure gauche, encadrée en rouge.
Si nous visualisons cette partie en plan serré, et que nous partons du postulat que ; pour la fonction de perte et que notre modèle prédit :
- Si le modèle prédit alors la perte est de
- Si le modèle prédit alors la perte est de
- Si le modèle prédit alors la perte est de
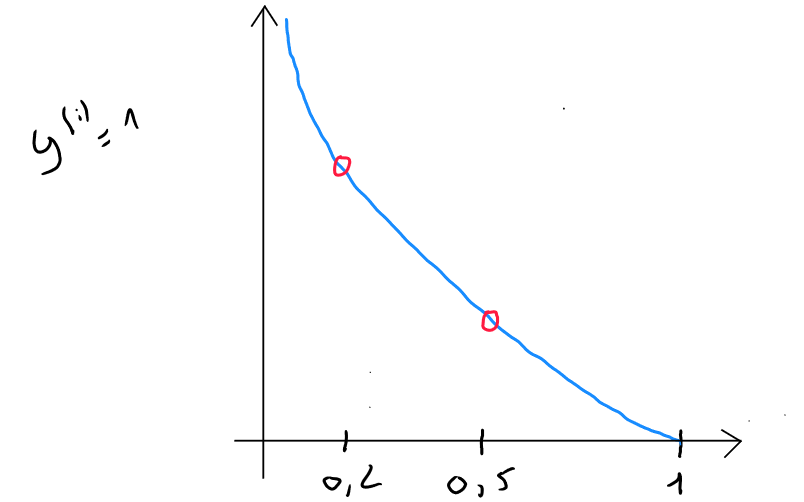
Ce que nous remarquons c'est que l'algorithme va tendre à réduire la perte et donc être le plus précis possible car les prédictions alors que vont créer une perte importante.
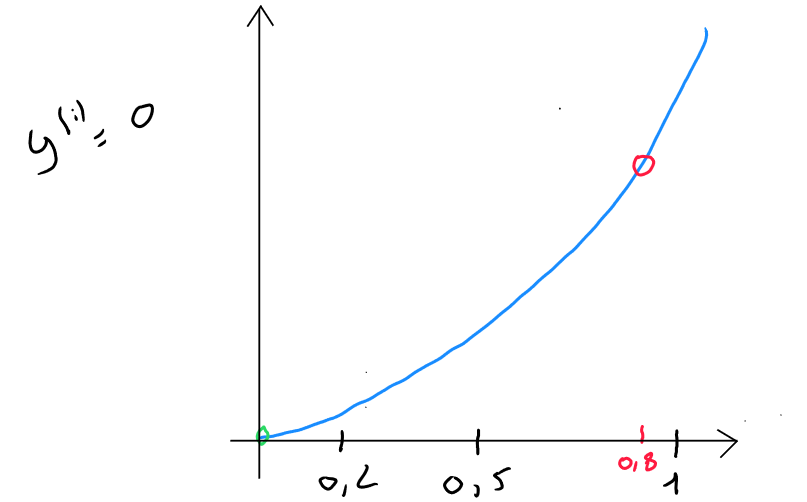
Dans le second cas ( ), l'algorithme va également tendre à réduire la perte et les prédictions alors que vont créer une perte importante.
Par conséquent, la transformation de la fonction de coût :
Nous permet d'obtenir une forme convexe et d'utiliser le gradient descent pour trouver l'optimal local.
Bien entendu, la fonction coût porte sur l'entièreté des données et correspondra donc à la somme des pertes divisées par :
L'algorithme du gradient descent cherchera donc à trouver les paramètres qui minimisent la fonction de coût.
La fonction de perte :
Peut être simplifiée comme suit :
Elle est simplifiée car elle correspond à la combinaison des deux cas ( ou ) et annule automatiquement un cas si l'autre est en hypothèse.
Si et que nous remplaçons les valeurs des dans la formule :
La partie de droite est annulée car et donc :
en conséquence, nous obtenons :
Si et que nous remplaçons les valeurs des dans la formule :
La partie de droite est annulée car et donc :
en conséquence, nous obtenons :
Rappelons-nous que la fonction de perte est une partie isolée de la fonction coût ( en bleu ) :
Fonction coût corrigée ( convexe )
Par conséquent, si nous souhaitons réécrire l'entièreté de la fonction coût, de petites transformation seront réalisées au niveau des opérateur et nous obtiendrons comme formule finale :
Cette fonction de coût finale est dérivée du principe de l'estimation de la probabilité maximale qui permet dans le cadre d'une régression logistique de trouver les paramètres et dans une forme convexe.
Fonction coût corrigée ( convexe ) en python
def compute_cost(X, y, w, b, lambda_= 1):
m, n = X.shape
cost = 0.
for i in range(m):
z = np.dot(X[i],w)+b
f_wb = sigmoid(z)
cost += -y[i]*np.log(f_wb) - (1-y[i])*np.log(1-f_wb)
total_cost = cost/m
#reg_cost = (lambda_ / (2 * m)) * np.sum(np.square(w))
#total_cost += reg_cost
return total_cost
Gradient descent
Tout comme l'algorithme du gradient descent de la régression linéaire , l'objectif du gradient descent dans le cadre de la régression logistique est de trouver le modèle qui minimise la fonction coût . La définition des valeurs de et permettra pour chaque nouvelle valeur de de définir la probabilité de d'appartenir à la classe ( la classe étant généralement la classe négative )..
Le formule complète du coût :
L'implémentation du gradient pour minimiser le coût correspond au même procédé que la régression linéaire, à savoir :
Pour chaque itération , il est important de définir, de manière temporaire la nouvelle valeur de w et la nouvelle valeur de b pour les remplacer par la suite de manière simultanée.
- ;
- ;
- ;
- ;
Cette définition des étapes du gradient descent ressemble entièrement à la régression linéaire. C'est tout à fait normal ; Ce qui change est la manière ensuite de définir le modèle :
- Dans la régression linéaire, nous retrouvons : ;
- Dans la régression logistique, nous appliquons soit ;
Même si l'algorithme du gradient descent semble similaire pour la régression linéaire et logistique, il s'agit bien de deux algorithmes différents étant donné la manière dont ils sont introduits par la suite dans le modèle.
Rapport des cotes
En statistique, l'Odd Ratio ( rapport des cotes ), est une mesure permettant de quantifier la force d'association entre une variable explicative ( donc un prédicteur ) et la probabilité d'occurrence de l'évènement que l'on souhaite prédire ( pour rappel, il s'agit de la classe positive qui signifie l'aspect négatif (Spam 1 , Non Spam 0 ; Malade 1 ; Non Malade 0 etc) ).
Le rapport des cotes évalue la variation de la probabilité de en fonction d'une augmentation d'une unité de la variable explicative.
imaginons que nous avons Patients. Sur les patients, sont malades et patients ont de la fièvre. Parmi les patients qui ont de la fièvre, sont malades et ne l'est pas. Le rapport des cotes va nous permettre de calculer la chance d'avoir de la fièvre quand on est malade par rapport au fait de ne pas être malade et avoir de la fièvre.
| Fièvre | Pas de fièvre | Total | |
|---|---|---|---|
| Malade | 3 (p) | 3 | 6 |
| Pas Malade | 1 (q) | 3 | 4 |
| Total | 4 | 6 | 10 |
Pour calculer le rapport des cotes, nous utilisons la formule suivante ( où est la proportion de malades ayant de la fièvre et est la proportion de non-malades ayant de la fièvre ) :
Dans notre exemple : soit soit
Soit :
Concernant le résultat obtenu, il représente le fait que les patients malades ont 3 fois plus de chance d'avoir de la fièvre que les patients non malades.
Cela ne signifie pas la probabilité d'avoir de la fièvre si on est malade ou d'être malade si on a de la fièvre ! Il s'agit simplement de l'association entre la maladie et la fièvre
En régression logistique, le rapport des cotes est calculé à partir du coefficient trouvé par la méthode du gradient descent. Le rapport des cotes pour une variable explicative est donné par . Par exemple, si le gradient descent identifie une valeur de de pour la fièvre, le rapport des cotes est donc . Cela signifie que les chances d'être malade augmentent de $3%* lorsqu'un patient a de la fièvre par rapport à un patient qui n'en a pas.
Toutefois, le rapport des chances ne sert pas dans le calcul de la probabilité mais permet de mieux comprendre le facteur multiplicatif de chance que l'évènement diminue ou augmente lorsque la variable explicative augmente d'une unité. Il permet donc de comparer plus facilement l'impact des différentes variables explicatives sur la probabilité de l'évènement.
Le rapport des chances permet de mieux comprendre le fonctionnement du modèle et les résultats.
Pour rappel, la probabilité sera calculée sur base de la valeur de d'un nouvel enregistrement et des valeurs de et identifiés par le gradient descent.
Gradient descent en python :
def compute_gradient(X, y, w, b, lambda_=1):
m, n = X.shape
dj_dw = np.zeros(w.shape)
dj_db = 0.
for i in range(m):
f_wb_i = sigmoid(np.dot(X[i],w) + b)
err_i = f_wb_i - y[i]
for j in range(n):
dj_dw[j] = dj_dw[j] + err_i * X[i,j]
dj_db = dj_db + err_i
dj_dw = dj_dw/m
dj_db = dj_db/m
dj_dw += (lambda_ / m) * w
return dj_db, dj_dw
Lancement du gradient descent:
def gradient_descent(X, y, w_in, b_in, cost_function, gradient_function, alpha, num_iters, lambda_):
m = len(X)
J_history = []
w_history = []
for i in range(num_iters):
dj_db, dj_dw = gradient_function(X, y, w_in, b_in, lambda_)
w_in = w_in - alpha * dj_dw
b_in = b_in - alpha * dj_db
if i<100000:
J_history.append( cost_function(X, y, w_in, b_in, lambda_))
if i > 1 and abs(J_history[-1] - J_history[-2]) < 0.000001:
print(f"Early stopping at iteration {i} as cost change is less than 0.000001")
break
if i% math.ceil(num_iters / 10) == 0:
print(f"Iteration {i:4}: Cost {J_history[-1]} ",
f"dj_dw: {dj_dw}, dj_db: {dj_db} ",
f"w_in: {w_in}, b_in:{b_in}")
return w_in, b_in, J_history, w_history
np.random.seed(1)
initial_w = np.zeros(X_train.shape[1])
initial_b = 0
lambda_=0.01
iterations = 1000
alpha = 0.003
w,b, J_history,_ = gradient_descent(X_train ,y_train, initial_w, initial_b,
compute_cost, compute_gradient, alpha, iterations, lambda_)
Régularisation
Le principe de régularisation d'une régression logistique est identique à ce que l'on retrouve pour de la fonction linéaire.
C'est à dire que dans le cadre d'un sous-apprentissage, l'option principale est d'ajouter des variables ou des enregistrements supplémentaires et en sur-apprentissage nous retrouvons également les options de base telles que l'augmentation ou la réduction de variables ( Sélection des Variables ) et l'augmentation des enregistrements.
Comme dans le cadre de la régression linéaire, la réduction du nombre de variables s'applique via le concept de l'ingénierie des caractéristiques ou par l'utilisation spécifiques de techniques.
Si pour des raisons spécifiques, nous devons en tant que data scientist, maintenir la sélection de toutes les variables, nous pouvons également palier au sur-apprentissage par l'application de la régularisation pour la régression logistique.
Rappelons que le concept de régularisation consiste à réduire l'impact de certaines variables par l'attribution d'un poids plus faible. Concrètement, l'idée est de faire en sorte que l'algorithme d'apprentissage réduise les valeurs des paramètres sans pour autant exiger de mettre des paramètres à . La régularisation s'applique principalement aux valeurs de même si l'on pourrait également considérer une régularisation sur le paramètre .
Cette pénalisation se fait par l'ajout de la régularisation suivante à la fonction coût modifiée de la régression logistique :
Gradient descent régularisé
- ;
- ;
- ;
- ;
Code python complet
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import math, copy
from sklearn.metrics import confusion_matrix
data = pd.read_csv('data.csv')
data
x = data[['x_1', 'x_2', 'x_3', 'x_4', 'x_5', '...', 'x_n']].values
y = data['y'].values
scaler_x = StandardScaler()
scaler_y = StandardScaler()
x = scaler_x.fit_transform(x)
y = scaler_y.fit_transform(y.reshape(-1, 1))
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.4, random_state=42)
#polynomial
"""
# Chargement des données
data = pd.read_csv('data.csv')
# Séparation des caractéristiques et de la cible
x = data[['x_1', 'x_2', 'x_3', 'x_4', 'x_5', '...', 'x_n']].values
y = data['y'].values
# Génération des termes polynomiaux de degré 3
poly = PolynomialFeatures(degree=3)
x_poly = poly.fit_transform(x)
# Standardisation des données polynomiales
scaler_x = StandardScaler()
x_poly = scaler_x.fit_transform(x_poly)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.4, random_state=42)
"""
# /Polynomial
def sigmoid(z):
g = 1/(1+np.exp(-z))
return g
def compute_cost(X, y, w, b, lambda_= 1):
m, n = X.shape
cost = 0.
for i in range(m):
z = np.dot(X[i],w)+b
f_wb = sigmoid(z)
cost += -y[i]*np.log(f_wb) - (1-y[i])*np.log(1-f_wb)
total_cost = cost/m
reg_cost = (lambda_ / (2 * m)) * np.sum(np.square(w))
total_cost += reg_cost
return total_cost
def compute_gradient(X, y, w, b, lambda_=1):
m, n = X.shape
dj_dw = np.zeros(w.shape)
dj_db = 0.
for i in range(m):
f_wb_i = sigmoid(np.dot(X[i],w) + b)
err_i = f_wb_i - y[i]
for j in range(n):
dj_dw[j] = dj_dw[j] + err_i * X[i,j]
dj_db = dj_db + err_i
dj_dw = dj_dw/m
dj_db = dj_db/m
dj_dw += (lambda_ / m) * w
return dj_db, dj_dw
def gradient_descent(X, y, w_in, b_in, cost_function, gradient_function, alpha, num_iters, lambda_):
m = len(X)
J_history = []
w_history = []
for i in range(num_iters):
dj_db, dj_dw = gradient_function(X, y, w_in, b_in, lambda_)
w_in = w_in - alpha * dj_dw
b_in = b_in - alpha * dj_db
if i<100000:
J_history.append( cost_function(X, y, w_in, b_in, lambda_))
if i > 1 and abs(J_history[-1] - J_history[-2]) < 0.000001:
print(f"Early stopping at iteration {i} as cost change is less than 0.000001")
break
if i% math.ceil(num_iters / 10) == 0:
print(f"Iteration {i:4}: Cost {J_history[-1]} ",
f"dj_dw: {dj_dw}, dj_db: {dj_db} ",
f"w_in: {w_in}, b_in:{b_in}")
return w_in, b_in, J_history, w_history
np.random.seed(1)
initial_w = np.zeros(X_train.shape[1])
initial_b = 0
lambda_=0.01
iterations = 1000
alpha = 0.003
w,b, J_history,_ = gradient_descent(X_train ,y_train, initial_w, initial_b,
compute_cost, compute_gradient, alpha, iterations, lambda_)
def predict(X, w, b):
m, n = X.shape
p = np.zeros(m)
for i in range(m):
z_wb = np.dot(X[i],w)
for j in range(n):
z_wb += 0
z_wb += b
f_wb = sigmoid(z_wb)
p[i] = 1 if f_wb>0.5 else 0
return p
p = predict(X_test, w, b)
confusion = confusion_matrix(y_test, p)
TP = confusion[1, 1] # True positive
FP = confusion[0, 1] # False positive
TN = confusion[0, 0] # True negative
FN = confusion[1, 0] # False negzative
print("Confusion matrix :")
print(confusion)
print("True positive (TP):", TP)
print("False positive (FP):", FP)
print("True negative (TN):", TN)
print("False negzative (FN):", FN)
Questions fréquentes
Qu'est-ce que la régression logistique ?
La régression logistique est un modèle de machine learning paramétrique utilisé pour le classement : il prédit les valeurs d'une variable qualitative à partir de prédicteurs. Plutôt que de prédire une classe directement, il renvoie une probabilité entre 0 et 1 qu'un nouvel enregistrement appartienne à une classe.
Quelle est la différence entre la régression linéaire et logistique ?
Les deux cherchent des relations entre une variable dépendante et des prédicteurs. La régression linéaire utilise une fonction linéaire pour modéliser une valeur, tandis que la régression logistique utilise une fonction sigmoïde avec une sous-fonction linéaire sous-jacente pour modéliser une probabilité entre 0 et 1 qu'un enregistrement appartienne à une classe.
Qu'est-ce que la fonction sigmoïde en régression logistique ?
La sigmoïde, ou fonction logistique, est une fonction en forme de S qui transforme n'importe quelle valeur en un nombre entre 0 et 1. Elle s'écrit f de z égale 1 divisé par 1 plus e à la puissance moins z, où e est la constante d'Euler et z la sous-fonction linéaire.
Qu'est-ce que le seuil de décision en régression logistique ?
Le seuil de décision est la valeur limite qui convertit la sortie de la sigmoïde en une classe. La littérature utilise souvent 0,5 : si la valeur prédite est supérieure ou égale à 0,5 la classe est 1, et si elle est inférieure à 0,5 la classe est 0. C'est le data scientist qui définit ce seuil.