Modélisation de données
Comment nous l'avons mentionné au chapitre précédent, l'informatique décisionnelle désigne des outils offrant des fonctionnalités d'ETL ( Extract - Transform and Load ). Une solution BI - un rapport contenant plusieurs Dashboard - permet de se connecter à une ou plusieurs sources de données.
Une source de données est une base de données contenant l'ensemble des informations issues d'un logiciel utilisé au quotidien par l'entreprise. La plupart des bases de données sont complexes car elles n'ont pas été conceptualisées pour des besoins d'analyse mais plutôt pour répondre à l'évolution constante du fonctionnement d'une entreprise. Par conséquent, une base de données évolue de manière régulière étant donné qu'un logiciel évolue également et subit au cours de son exploitation de nombreuses modifications / adaptations.
Prenons l'exemple d'un hôpital qui construit une nouvelles annexe pour de nouveaux soins et qui utilise divers logiciels au quotidien : un ERP de comptabilité / Achat, un logiciel « dossier patient », un logiciel d'admission et de facturation patient, un logiciel pharmacie, etc. La création d'une nouvelle annexe aura une incidence sur l'ensemble de ces logiciels dont l'architecture des bases de données devra être modifiée.Cette modification peut être mineure ( l'ajout de nouvelle unité de soins ) ou majeure ( le changement d'une législation qui implique qu'un champ de la base de donné doit être calculé d'une manière x avant une certaine date et de manière y à une autre date ). Il est possible également que l'ajout de l'unité de soin dans les tables correspondantes aux anciennes unités de soins ne soit pas possible pour des raison x ou y d'interdépendance entre des tables et que pour prévenir l'évolution future, à partir d'une certaine date - apparition des nouvelles unités de soins -, toutes les informations sont dirigées vers de nouvelles tables de sorte que les informations doivent être reprises des anciennes tables avant une certaine date et des nouvelles tables après cette même date.
Il est également probable que de nombreuses variables ( colonnes de tables ) contiennent des valeurs considérées comme aberrantes ou erronées étant donné certaines flexibilités obligatoires du logiciel pour répondre à des cas spécifiques métiers.
Par exemple, un patient dont le genre est masculin qui a eu dans le passé des soins en maternité ; un patient de 30 ans qui se retrouve en service gériatrique ; un patient dont l'âge est de 442 ans ; etc.Toute données requiert un examen approfondi des variables disponibles analyse statistique univariée ainsi que la préparation, transformation des informations - Ingénierie des caractéristiques .
En informatique décisionnelle, la modélisation de données peut être scindée en deux parties :
- La transformation de données : transformation des valeurs de colonnes existantes ou la création de nouvelles colonnes à partir de colonnes existantes
- La simplification du modèle relationnel en un schéma en étoile pour assurer l'efficience de l'outil
Transformation de données
La transformation de données consiste à appliquer des fonctions sur des variables existantes pour soit transformer des valeurs ( corriger des valeurs ) soit créer des valeurs à partir de valeurs existantes.
Prenons l'exemple de l'hôpital, dans la table « Patient », nous retrouvons les colonnes « First Name » et « Last Name » et, pour des besoins précis en visualization de données, nous somme amené à créer une nouvelles colonne « Patient Name » dont le résultat serait la combinaison des deux colonnes précitées. Cette opération correspond à la création d'une nouvelle variable sur base de variables existantes. Autre exemple, dans la table qui reprend les unités de soins ( UDS ), nous retrouvons dans une source de données les valeurs UDSFA1 et UDSFA2 alors que dans une autre source de données, nous ne retrouvons que la valeur UDSFA. Cette dernière terminologie USDFA est néé de la fusion des unités de soins UDSFA1 et UDSFA2 suite à une nouvelle législation de financement, mais l'un des logiciel ( admission ) n'a pas été mis à jour. Par conséquent, nous utiliserons une formule pour transformer les valeurs existantes et donner l'instruction au logiciel de remplacer les valeurs UDSFA1 et UDSFA2 par UDSFA à partir d'une certaine date.La transformation des données peut se faire soit via un éditeur de code - intégré dans la plupart des outils - et dans ce cas, le data architecte utilise un langage spécifique à l'outil pour appliquer ces modifications, soit il existe - également dans les plupart des outils - , des interface « low code » permettant à l'utilisateur d'appliquer de nombreuses modifications via une interface conviviale à l'aide de sélections spécifiques. Les modifications au niveau de l'outil BI n'impactent pas la source de données, il s'agit d'instruction de code qui s'exécute dans l'outil BI, au moment du rechargement des données - soit la lecture des données originales.
La transformation de données inclut également un ensemble de modifications mineures - mise en forme - tel que le fait de renommer une variable, changer le data type, modifier le formatage, extraire une partie de l'information, etc.
Star Schéma
Lorsqu'un data architecte intervient pour la création d'une application en informatique sur l'une ou plusieurs sources de données, il est en son devoir d'assurer l'efficience de l'application et doit, en conséquence, revoir le schéma relationnel des tables. Il est important de comprendre que par défaut, lorsqu'un utilisateur fait une sélection dans un Dashboard - filtre l'information -, l'outil réagit de manière instantanée, c'est à dire que les visuels s'adaptent à la sélection.
La raison est simple : la requête formée par l'utilisateur n'est pas envoyée à la source de données mais directement à l'outil BI qui, lors du chargement des données ( l'extraction depuis une ou plusieurs sources ) créée une copie de l'information. L'utilisateur n'interroge donc plus la source de données originale mais le schéma de donné de l'outil. Cette copie de l'information est réalisée selon des échéances spécifiques au regard du besoin de rafraichissement de l'information ( 1x par jour, toutes les heures, toutes les 5 minutes ). Un utilisateur peut également à n'importe quel moment exécuter le script pour mettre à jour l'information, c'est à dire charger les nouvelles données qui ont été enregistrées dans le base de données depuis la dernière copie. Bien entendu, la copie des informations dans la mémoire de l'outil est l'état par défaut, mais dans certains cas - notamment pour les tables présentant de nombreuses informations ( les tables de faits ), - il est possible d'être connecté directement depuis la source de données et obtenir un rafraichissement continu pour cette table.
Le premier élément qui favorise l'efficience de réactivité d'un outil en informatique décisionnel est le fait que la requête «n'attaque pas» directement la source de données. Le second élément est le fait que le data architect a pour mission de simplifier le schéma relationnel entre les tables et tendre vers ce que l'on appelle un datamart - un schéma en étoile.
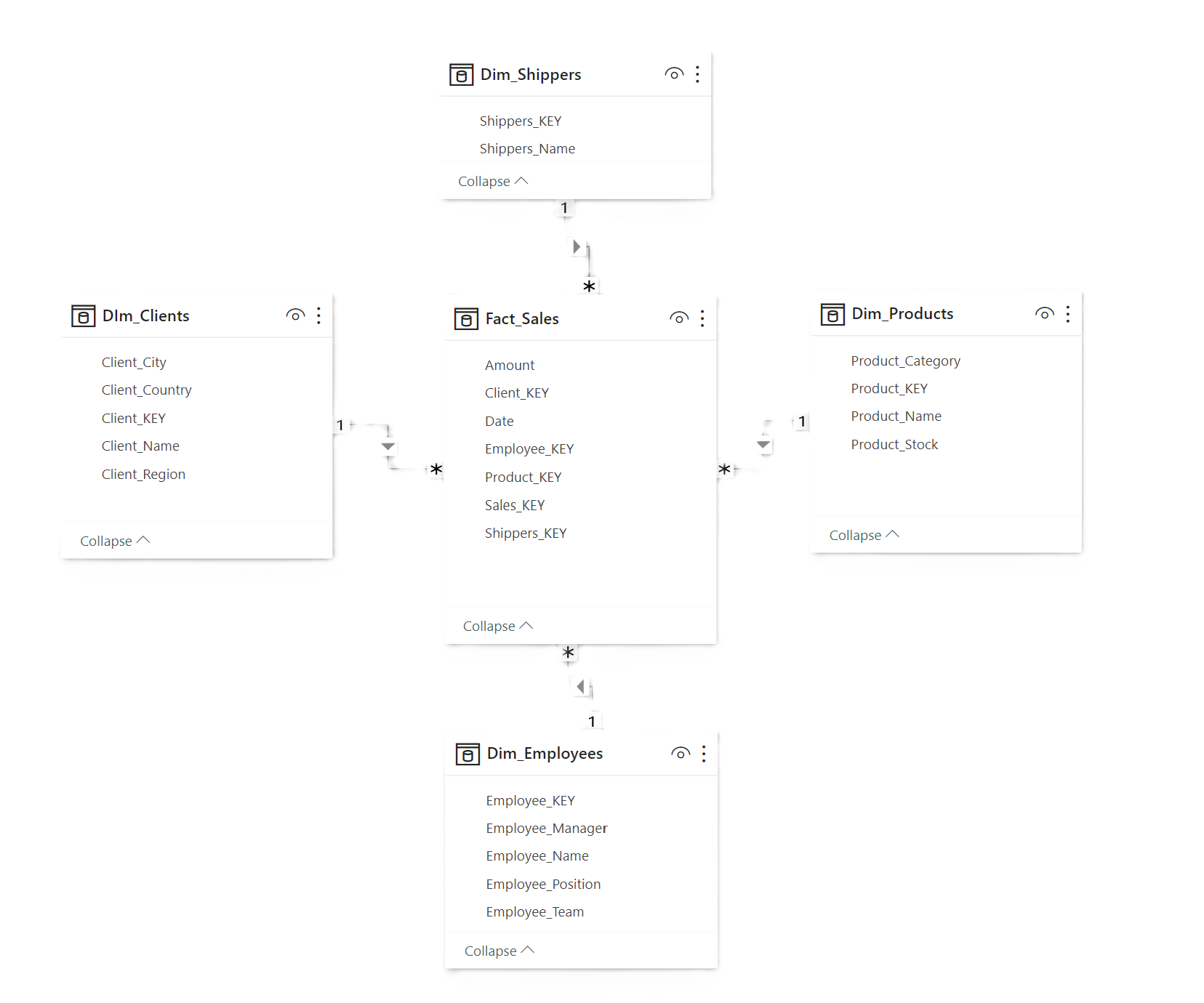
Table transactionnelle & tables de dimensionnelles
Le schéma en étoile est l'approche la plus utilisée en informatique décisionnelle et également dans les datawarehouse pour favoriser l'efficience des outils d'analyse de données. Le schéma en étoile consiste à créer un datamart, c'est à dire un schéma simplifié dans lequel on retrouve :
- Une table de faits - table transactionnelle - qui se trouve au centre du schéma. Il s'agit de la table principale qui contient tous les évènements ou les transactions. Une table de faits est facilement identifiable car elle contient en général de nombreuses lignes pour un nombre de colonnes limité aux colonnes clés qui se rapportent aux tables de dimension et des colonnes de mesures ( variables quantiative ) ainsi qu’une notion temporelle - colonne date ( ou timestamp ).
- Des tables de dimensions qui contiennent une ou plusieurs colonnes clés ainsi que les informations dimensionnelles allant au délà de la clé. Les tables de dimensions contiennent de nombreuses colonnes mais peu de lignes en général et servent principalement à filtrer les mesures
La relation entre une table de dimension et une table de faits est de 1 à plusieurs (1 - *). Un enregistrement unique dans la table de dimension est lié à plusieurs enregistrements dans la table de faits.
Normalisation & dénormalisation
Une table de fait est normalisée : la normalisation décrit des données stockées de manière à réduire les informations répétitives. Par exemple, une table produit, contient la clé produit ainsi que de nombreuses colonnes liées aux informations relatives à cette clé ( le nom du produit, la categorie du produit etc ). Dans la table de faits, il n'est pas nécessaire de répéter les informations qui sont liées à la clé et vont au delà de cette information. La clé elle seule suffit pour relier l'ensemble de l'information. On dit donc que la table est normalisée - le nombre de colonne est réduit au maximum au strict nécessaire.
A contrario, une table de dimension est dénormalisée : la dénormalisation décrit des données stockées en tenant compte de toutes les informations. La table de dimension produits contient la clé produit ainsi que tous les champs qui vont au delà de cette clé, à savoir le nom du produit, la catégorie etc.
Table de faits ( ventes ) normalisée
| Sales_Key | Product_Key | Customer_Key | Date | Quantity | Amount |
|---|---|---|---|---|---|
| 1 | 101 | 1 | 2024-01-01 | 2 | 100 |
| 2 | 102 | 2 | 2024-02-15 | 1 | 50 |
| 3 | 101 | 1 | 2024-03-20 | 3 | 150 |
| 4 | 103 | 3 | 2024-04-10 | 5 | 250 |
Table de faits ( ventes ) dénormalisée
| Sales_Key | Prod_Key | ProductName | Category | Cust_Key | CustomerName | City | Date | Quantity | Amount |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 101 | Product A | Electronics | 2 | John Doe | New York | 2024-01-01 | 2 | 100 |
| 2 | 102 | Product B | Clothing | 1 | Jane Smith | London | 2024-02-15 | 1 | 50 |
| 3 | 101 | Product A | Electronics | 3 | John Doe | New York | 2024-03-20 | 3 | 150 |
| 4 | 103 | Product C | Books | 5 | Alice Brown | Paris | 2024-04-10 | 5 | 250 |
Un data architecte chargera toujours table par table depuis une source de données afin de pouvoir conceptualiser le star schéma, c'est à dire regrouper les informations transactionnelles dans une table centrale - unique - ainsi que l'ensemble des clés ; de normaliser cette table transactionnelle et ajouter au modèle un ensemble de tables dimensionnelles dénormalisées
Fusion des tables
Pour arriver à la création d'un star schéma, c'est à dire de regrouper ( fusionner ) un ensemble de tables en un nombre limité dans un modèle simplifié, le data architect à deux possibilités :
- Appliquer une fonction de jointure pour ajouter les colonnes d'une table B à une table A sur base des valeurs d'une ou plusieurs colonne clés communes. Il s'agit de la fonction JOIN qui peut prendre différents préfixes ( outer,inner,left,right ).
- Appliquer une fonction de concatenation ( axe horizontal - également UNION ) pour ajouter les enregitrements d'une table X en dessous des enregistrements d'une table Y sur base ( en général ) de plusieurs ( voir toutes ) des colonnes communes.
Join
La jointure permet donc d'ajouter la ou les colonnes d'une table B dans une table A, à condition que les deux tables disposent d'une à plusieurs colonnes communes et des valeurs communes au sein de ces colonnes.
Nous retrouvons ci-dessous deux tables - séparées dans le modèle de données - ; La table des produits ( produits liés à la pratique du Yoga ), et la table des categories. Nous souhaitons regrouper ces tables ( les fusionner ), c'est à dire, intégrer CategoryName de la table catégorie dans la table des produits. Les deux tables disposent d'une colonne commune (CategoryID) dont la plupart des valeurs sont communes.
Nous constatons, dans les tables ci-dessous, que la table produits contient un produit ( Yoga Perfurme ) lié à un ID de catégorie 6 qui n'existe pas dans la table catégories et nous constatons que nous avons la catégorie 5 dans la table Catégories pour laquelle nous n'avons aucun produit liés dans la table produits
| ProductID | Product | CategoryID |
|---|---|---|
| 64 | Mat Green | 1 |
| 65 | Mat Blue | 1 |
| 66 | Mat Cleaner | 2 |
| 67 | Yoga Bricks | 2 |
| 68 | Mat Straps | 3 |
| 69 | Mat Bag | 3 |
| 70 | Trousers | 4 |
| 71 | Legging | 4 |
| 72 | Yoga Perfume | 6 |
| CategoryID | CategoryName |
|---|---|
| 1 | Yoga Mat |
| 2 | Yoga Accessories |
| 3 | Yoga Mat Bag |
| 4 | Women Yoga Clothes |
| 5 | Men Yoga Clothes |
Full Outer Join
Par défaut, si nous souhaitons fusionner les deux tables, la fonction de fusion intégrera dans la table résultante ( la table finale qui sera unique ) - toutes les valeurs de la table A et toutes les valeurs de la table B ; C'est ce que l'on appelle un Outer Join - aucune information n'est perdue suite à la fusion.
La fonction en python provient de la librairie pandas (pd.merge)
import pandas as pd
# Full outer join
df_final = pd.merge(df_products, df_categories, on='CategoryID', how='outer')
# Remplissage des valeurs manquantes avec 'N/A'
df_final.fillna('N/A', inplace=True)
df_final
Et nous obtenons la table résultante suivante :
| ProductID | Product | CategoryID | CategoryName |
|---|---|---|---|
| 64 | Mat Green | 1 | Yoga Mat |
| 65 | Mat Blue | 1 | Yoga Mat |
| 66 | Mat Cleaner | 2 | Yoga Accessories |
| 67 | Yoga Bricks | 2 | Yoga Accessories |
| 68 | Mat Straps | 3 | Yoga Mat Bag |
| 69 | Mat Bag | 3 | Yoga Mat Bag |
| 70 | Trousers | 4 | Women Yoga Clothes |
| 71 | Legging | 4 | Women Yoga Clothes |
| 72 | Yoga Perfume | 6 | N/A |
| N/A | N/A | 5 | Men Yoga Clothes |
Inner Join
Le préfixe Inner supprime de la table finale tous les enregistrements qui ne sont pas communs aux deux tables. C'est à dire toutes les valeurs des clés CategoryID non présentes dans les deux tables. En conséquence, si nous avons un ou plusieurs produits dont une catégorie n'existe pas dans la table categories et une ou plusieurs catégories dans la table catégories pour laquelle nous n'avons aucun CategoreID dans la table produits, ce ou ces enregistrements disparaitrons.
Par exemple, dans notre cas, la table finale ne contiendra pas le ProductID - lié à aucune catégorie - ni la catégorie 5 non reprise dans la table produits.| ProductID | Product | CategoryID |
|---|---|---|
| 64 | Mat Green | 1 |
| 65 | Mat Blue | 1 |
| 66 | Mat Cleaner | 2 |
| 67 | Yoga Bricks | 2 |
| 68 | Mat Straps | 3 |
| 69 | Mat Bag | 3 |
| 70 | Trousers | 4 |
| 71 | Legging | 4 |
| 72 | Yoga Perfume | 6 |
| CategoryID | CategoryName |
|---|---|
| 1 | Yoga Mat |
| 2 | Yoga Accessories |
| 3 | Yoga Mat Bag |
| 4 | Women Yoga Clothes |
| 5 | Men Yoga Clothes |
Nous spécifions dans la fonction python le « how » et cette fois-ci il s'agit d'un inner.
import pandas as pd
# Inner join
df_final = pd.merge(df_products, df_categories, on='CategoryID', how='inner')
df_final
Et nous obtenons la table résultante suivante :
| ProductID | Product | CategoryID | CategoryName |
|---|---|---|---|
| 64 | Mat Green | 1 | Yoga Mat |
| 65 | Mat Blue | 1 | Yoga Mat |
| 66 | Mat Cleaner | 2 | Yoga Accessories |
| 67 | Yoga Bricks | 2 | Yoga Accessories |
| 68 | Mat Straps | 3 | Yoga Mat Bag |
| 69 | Mat Bag | 3 | Yoga Mat Bag |
| 70 | Trousers | 4 | Women Yoga Clothes |
| 71 | Legging | 4 | Women Yoga Clothes |
Left Join
Le préfixe left est le plus utilisé. Il s'agit de charger tous les enregistrement de la table A mais ne garder de la table B que les valeurs des clés communes. Ce préfixe supprime donc de la table finale tous les enregistrements de la table B dont les valeurs de la clé CategorieID n'existent pas dans la table A. En conséquence, si nous avons une ou plusieurs catégories qui n'existent pas dans la table produits, ces lignes ne seront pas chargées dans la table finale.
Par exemple, dans notre cas, la table finale ne contiendra pas la catégorie 5 liée à aucun produit ; mais gardera le ProductID - lié à aucune catégorie.| ProductID | Product | CategoryID |
|---|---|---|
| 64 | Mat Green | 1 |
| 65 | Mat Blue | 1 |
| 66 | Mat Cleaner | 2 |
| 67 | Yoga Bricks | 2 |
| 68 | Mat Straps | 3 |
| 69 | Mat Bag | 3 |
| 70 | Trousers | 4 |
| 71 | Legging | 4 |
| 72 | Yoga Perfume | 6 |
| CategoryID | CategoryName |
|---|---|
| 1 | Yoga Mat |
| 2 | Yoga Accessories |
| 3 | Yoga Mat Bag |
| 4 | Women Yoga Clothes |
| 5 | Men Yoga Clothes |
Nous spécifions dans la fonction python le « how » et cette fois-ci il s'agit d'un left.
import pandas as pd
# Left join
df_final = pd.merge(df_products, df_categories, on='CategoryID', how='left')
# Remplissage des valeurs manquantes avec 'N/A'
df_final.fillna('N/A', inplace=True)
df_final
Et nous obtenons la table résultante suivante :
| ProductID | Product | CategoryID | CategoryName |
|---|---|---|---|
| 64 | Mat Green | 1 | Yoga Mat |
| 65 | Mat Blue | 1 | Yoga Mat |
| 66 | Mat Cleaner | 2 | Yoga Accessories |
| 67 | Yoga Bricks | 2 | Yoga Accessories |
| 68 | Mat Straps | 3 | Yoga Mat Bag |
| 69 | Mat Bag | 3 | Yoga Mat Bag |
| 70 | Trousers | 4 | Women Yoga Clothes |
| 71 | Legging | 4 | Women Yoga Clothes |
| 72 | Yoga Perfume | 6 | N/A |
Right Join
Le préfixe right est le moins utilisé. Il s'agit de charger tous les enregistrement de la table B mais ne garder de la table A que les valeurs des clés communes à la table B. Ce préfixe supprime donc de la table finale tous les enregistrements de la table A dont les valeurs de la clé CategorieID n'existent pas dans la table B. En conséquence, si nous avons un ou plusieurs produits qui existent dans la table produits, mais lié à aucune catégorie dans la table catégories ces lignes ne seront pas chargées dans la table finale.
Par exemple, dans notre cas, la table finale ne contiendra le produit 72 lié à aucune catégorie ; mais gardera la CategoreID - liée à aucun produit.| ProductID | Product | CategoryID |
|---|---|---|
| 64 | Mat Green | 1 |
| 65 | Mat Blue | 1 |
| 66 | Mat Cleaner | 2 |
| 67 | Yoga Bricks | 2 |
| 68 | Mat Straps | 3 |
| 69 | Mat Bag | 3 |
| 70 | Trousers | 4 |
| 71 | Legging | 4 |
| 72 | Yoga Perfume | 6 |
| CategoryID | CategoryName |
|---|---|
| 1 | Yoga Mat |
| 2 | Yoga Accessories |
| 3 | Yoga Mat Bag |
| 4 | Women Yoga Clothes |
| 5 | Men Yoga Clothes |
Nous spécifions dans la fonction python le « how » et cette fois-ci il s'agit d'un right.
import pandas as pd
# Right join
df_final = pd.merge(df_products, df_categories, on='CategoryID', how='right')
# Remplissage des valeurs manquantes avec 'N/A'
df_final.fillna('N/A', inplace=True)
df_final
Et nous obtenons la table résultante suivante :
| ProductID | Product | CategoryID | CategoryName |
|---|---|---|---|
| 64 | Mat Green | 1 | Yoga Mat |
| 65 | Mat Blue | 1 | Yoga Mat |
| 66 | Mat Cleaner | 2 | Yoga Accessories |
| 67 | Yoga Bricks | 2 | Yoga Accessories |
| 68 | Mat Straps | 3 | Yoga Mat Bag |
| 69 | Mat Bag | 3 | Yoga Mat Bag |
| 70 | Trousers | 4 | Women Yoga Clothes |
| 71 | Legging | 4 | Women Yoga Clothes |
| N/A | N/A | 5 | Men Yoga Clothes |
Concaténation
Appliquer une fonction de concatenation ( axe horizontal - également UNION ) consiste à ajouter les nouveaux enregitrements d'une table X à des enregistrements existants d'une table Y. Les nouveaux enregistrements sont intégrés à la table comme étant des nouvelles lignes. La concatenation s'applique en général entre deux tables ayant une structure quasi parfaitement identiques.
| ProductID | Product |
|---|---|
| 64 | Mat Green |
| 65 | Mat Blue |
| 66 | Mat Cleaner |
| 67 | Yoga Bricks |
| 68 | Mat Straps |
| 69 | Mat Bag |
| 70 | Trousers |
| 71 | Legging |
| 72 | Yoga Perfume |
| ProductID | Product | Code |
|---|---|---|
| 73 | Mat Red | 654983211 |
| 74 | Sandbag | 953625923 |
| 75 | Cylindrical Bolster | 278534109 |
Voici le code python :
import pandas as pd
df_final = pd.concat([df1, df2], ignore_index=True)
df_final = df_final.fillna('NA')
df_final
df_final
Et nous obtenons la table résultante suivante :
| ProductID | Product | Code |
|---|---|---|
| 64 | Mat Green | N/A |
| 65 | Mat Blue | N/A |
| 66 | Mat Cleaner | N/A |
| 67 | Yoga Bricks | N/A |
| 68 | Mat Straps | N/A |
| 69 | Mat Bag | N/A |
| 70 | Trousers | N/A |
| 71 | Legging | N/A |
| 72 | Yoga Perfume | N/A |
| 73 | Mat Red | 654983211 |
| 74 | Sandbag | 953625923 |
| 75 | Cylindrical Bolster | 278534109 |
Découvrez-en plus sur eaqbe.com :
-
Découvrez nos services de consultance en data modelling : https://www.eaqbe.com/fr/solutions/services
-
Explorez nos programmes de formation en data modelling : https://www.eaqbe.com/fr/solutions/trainings
Développez votre expertise avec des sessions de formation ciblées. -
Rencontrez l'équipe eaqbe experte en modélisation : https://www.eaqbe.com/fr/eaqbe-team
Découvrez les personnes qui impulsent l'innovation et l'excellence chez eaqbe.
Questions fréquentes
Qu'est-ce que la modélisation de données en informatique décisionnelle ?
La modélisation de données en informatique décisionnelle comporte deux parties : transformer les valeurs de colonnes existantes ou créer de nouvelles colonnes, et simplifier le modèle relationnel en un schéma en étoile pour assurer l'efficience de l'outil.
Qu'est-ce qu'un schéma en étoile ?
Un schéma en étoile, aussi appelé datamart, est un schéma simplifié avec une table de faits au centre qui contient tous les évènements ou transactions, entourée de tables de dimensions qui contiennent les informations descriptives et servent à filtrer les mesures.
Quelle est la différence entre une jointure et une concaténation ?
Une jointure ajoute les colonnes d'une table B à une table A sur base de valeurs de clés communes, avec les préfixes outer, inner, left ou right. Une concaténation, aussi appelée union, ajoute les enregistrements d'une table en dessous de ceux d'une autre sur l'axe horizontal.
Quelle est la différence entre une table normalisée et une table dénormalisée ?
Une table de faits est normalisée : elle stocke les données en réduisant les informations répétitives en ne gardant que les clés et les mesures. Une table de dimension est dénormalisée : elle stocke tous les champs au-delà de la clé, comme le nom et la catégorie du produit.